# 14/08/20 - Robby The Robot
I wrote a technical version of this tutorial called Optimising a Rubbish Collection Strategy with Genetic Algorithms (opens new window) which was published on Towards Data Science.
A couple of years ago I read a fantastic book on complex systems by Melanie Mitchell called "Complexity: A Guided Tour". I highly recommend it if you're a big nerd like me and find questions (from the blurb) like these interesting:
What enables individually simple insects like ants to act with such precision and purpose as a group? How do trillions of neurons produce something as extraordinarily complex as consciousness?
One of my favourite chapters was about a set of optimisation techniques known as "Genetic Algorithms" which utilise principles inspired by natural selection. I'm fascinated by the intersection of different disciplines and so GAs (and the associated combination of biology and computer science) has been of interest to me for a while. In my area of data science GAs can be used for hyper-parameter optimisation, but unfortunately I am yet to find a feasible opportunity to try them out since they tend to be computationally expensive.
While maybe not the most practical set of algorithms, in my opinion they are among the most beautiful. Below is a description of my Python implementation of the Robby Robot genetic algorithm, described in Mitchell's book.
# Problem
A robot named Robby lives in a two-dimensional grid world full of rubbish and surrounded by 4 walls (shown below). The aim of this project is to evolve an optimal control strategy for Robby that will allow him to pick up rubbish efficiently and not crash into walls. Robby can only see the four squares NESW of himself as well as the square he is in. There are 3 options for each square; it can be empty, have rubbish in it or be a wall. Therefore there are 3⁵ = 243 different scenarios Robby can be in. Robby can perform 7 different actions; move NESW, move randomly, pickup rubbish or stay still. Robby's control strategy can therefore be encoded as a "DNA" string of 243 digits between 0 and 6 (corresponding to the action Robby should take in each of the 243 possible situations).
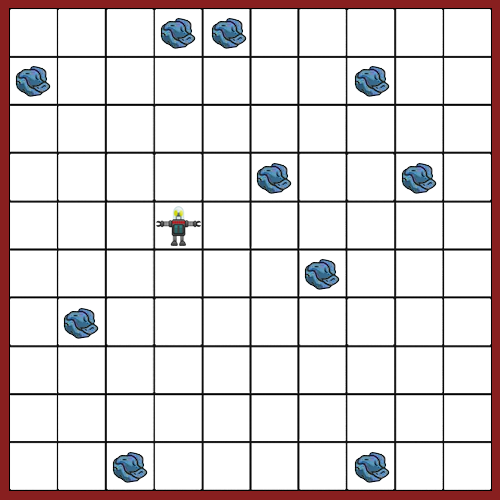
# Approach
Genetic algorithms are a family of optimisation techniques that loosely resemble evolutionary processes in nature. In broad terms the steps are:
- An initial "population" of random solutions to a problem are generated
- The "fitness" of each individual is assessed based on how well it solves the problem
- The fittest solutions "reproduce" and pass on "genetic" material to offspring in the next generation
- Repeat steps 1 to 3 until we are left with a population of optimised solutions
To solve this problem, you create a first generation of Robbys initialised to random DNA strings. You then simulate letting these robots run around in randomly assigned grid worlds and see how they perform. A robot's fitness is a function of how many pieces of rubbish it picked up in n moves and how many times it crashed into a wall. The robots then "mate" with probabilities linked to their fitness (i.e. robots that picked up lots of rubbish are more likely to reproduce) and a new generation is created.
There are a few different ways that "mating" can be implemented. In Mitchell's version she took the 2 parent DNA strings, randomly spliced them and then joined them together to create a child for the next generation. In my implementation I assigned each gene probabilistically from each parent (i.e. for each of the 243 genes, I flip a coin to decide which parent will pass on their gene). Here are the first 10 genes of 2 parents and a possible child using my method:
Parent 1: 1440623161
Parent 2: 2430661132
Child: 2440621161
Another concept from natural selection that we replicate with this algorithm is that of "mutation". While the vast majority of genes in a child will be passed down from a parent, I have also built in a small possibility that the gene will mutate (i.e. will be assigned at random). This mutation rate gives us the ability to control the trade-off between exploration and exploitation.
While initially most of the robots pick up almost no rubbish and consistently crash into walls, within a few generations we start to see simple strategies (such as "if in square with rubbish, pick it up" and "if next to wall, don't move into wall") propogate through the population. After a few hundred iterations, we are left with a generation of incredible rubbish-collecting geniuses.
# Results
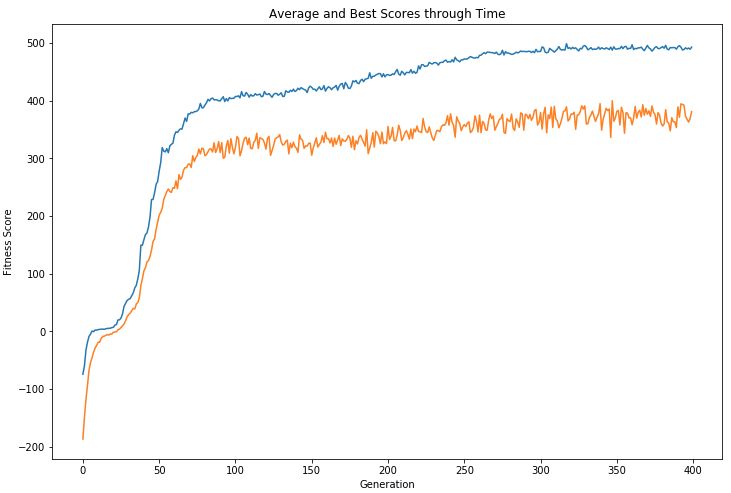
The plot below shows that we were able to "evolve" a successful rubbish collection strategy in 400 generations.
To assess the quality of these control strategies, I manually created a benchmark strategy with some intuitively sensible rules:
- If rubbish is in current square, pick it up
- If rubbish is visible in an adjacent square, move to that square
- If next to a wall, move in the opposite direction
- Else, move in a random direction
On average, this benchmark strategy achieved a fitness score of 426.9 but this was no match for our final "evolved" robot which had an average fitness score of 475.9.
# Strategy Analysis
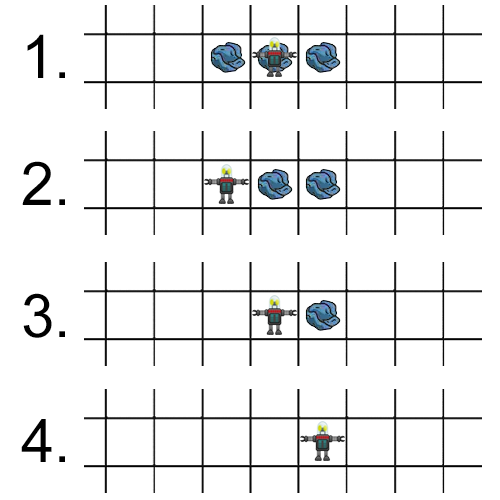
One of the coolest things about this approach to optimisation is that you can find counter-intuitive solutions. Not only were the robots able to learn sensible rules that a human might design, they also spontaneously came up with strategies that humans might never consider. One sophisticated technique that emerged was the use of "markers" to overcome short-sightedness and a lack of memory. For example, if a robot is currently in a square with rubbish in it and can see rubbish in the squares to the east and west, the robot performs the following steps:
- move to the west (leave the rubbish in the current square as a marker)
- pick up the rubbish and move back to the east (it can see the rubbish left as a marker)
- pick up the rubbish and move to the east
- pick up the final piece of rubbish
Another example of counter-intuitive strategies emerging from this kind of optimisation is shown below. OpenAI taught agents to play hide and seek using reinforcement learning (a more sophisticated optimisation approach). We see that the agents learn "human" strategies at first but eventually learn novel solutions such as "Box Surfing" that exploit the physics of OpenAIs simulated environment.
# Code
The code for my implementation (including a demo notebook) is available on GitHub (opens new window).